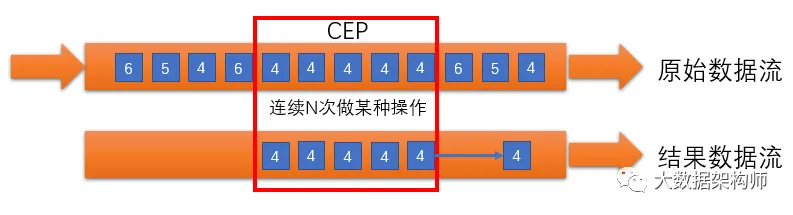
概念
如上图所示,假设我们对模式 A、B、B、C 感兴趣,它代表我们想要找到这样的事件序列:
- A 类事件发生
- B 类事件发生两次
- C 类事件发生
从事件流中匹配出 a1、b1、b2、c1 的具体事件。注意,这里我们并不要求事件之间是严格连续的
flink-cep 分为 3 个核心概念:
- 模式(
Pattern) - 事件流(
DataStream<Event>) - 匹配结果(
Match)
flink-cep 的应用场景有:
- 实时风控。
- 风险用户检测。5 分钟内转账次数超过 10 次且金额大于 10000
- 实时营销。滴滴的一些实时营销场景:
- 乘客线上冒泡 1 分钟没罚单
- 乘客下单后 2 分钟内没司机接单
- 乘客在不同业务线之间比价
- 实时规则检测。
- 直播实时检测。检测到 10 分钟内观看人数持续下跌,实时推送直播达人,调整直播策略
- 用户在 30 分钟内创建多笔订单,没有支付,疑似刷单,进行账号封禁
- 爆品发现。某款商品 5 分钟内成交超过 1000 单,实时推送商家,提醒及时补货、直播间挂链接
- 在线奖励。当完成在线任务后,及时发放积分和奖励
1.模式
模式有 3 种:
- 单个模式
- 组合模式
- 模式组
1.1 单个模式
1.1.1 条件(Conditions)
可以指定一个条件来决定事件是否进入这个模式:
- 条件可以很简单,比如
value > 5或name contains "SB"等 - 条件可以是很复杂的,由多个条件组合、具有层级的筛选规则组成,形成组合条件树
组合条件树需包含 2 个概念:
- 可组合。可通过
且或条件进行组合 - 可分层。条件不只是简单的
value > 5还可以是复合条件如18 < age < 60 and sex == "man"
比如想捞取身体健康、无犯罪史、女性年龄在 18 ~ 60 或男性在 18 ~ 65 岁之间的用户:
可用 JSON 表达如下:
1.1.2 量词
如果只能检测到单个事件(虽然单个事件的匹配规则可能很复杂,但也只能匹配一个事件),会使用受限。flink-cep 也可以支持对模式增加量词,表达事件的重复次数。
模式类型:
- 单例模式。只能匹配一次
- 循环模式。可重复匹配
比如在金融风控场景,检测用户连续转账 5 次且每次转账金额大于 10000 的行为,暂时封禁用户账号,防止被诈骗。转账事件定义如下,金额单位:分
想检测到转账金额大于 10000,条件为 action == "transfer" and amount >= 1000000,接下来需要检测事件重复次数超过 5 次。5 次即为量词:
- 单例模式。
action == "transfer" and amount >= 1000000 - 循环模式。设置
action == "transfer" and amount >= 1000000重复次数超过 5 次
在 flink-cep 中实现如下:
flink-cep 支持的量词如下:
times(5)。期望出现 5 次times(1, 3)。期望出现 1 ~ 3 次timesOrMore(5)。期望出现 5 次或更多oneOrMore()。等价于timesOrMore(1)opitonal()。可将量词变成可选,加上optional()表示可以不发生times(5).optional()。表示可以出现 5 次,也可出现 0 次times(1, 3).optional()。表示可以出现 1 ~ 3 次,也可以出现 0 次timesOrMore(5).optional()。表示可以出现 5 次或更多,也可出现 0 次
greedy()。期望尽可能多的重复,比如一个期望一个事件重复 3 次,实际上出现 10 次,匹配的时候期望把 10 次全拿出来作为一个结果,而不是把 10 次作为 3 + 3 + 3,给了 3 个结果。times(5).greedy()。表示可以出现 5 次,并尽可能的重复次数多times(1, 3).greedy()。表示可以出现 1 ~ 3 次,并尽可能的重复次数多timesOrMore(5).greedy()。表示可以出现 5 次或更多,并尽可能的重复次数多
optinonal和greedy()也可以一起使用times(5).optional().greedy()。表示可以出现 5 次,也可以出现 0 次,并尽可能的重复次数多
1.2 组合模式
比如在网站流量场景,通过埋点不断获取到用户在网页的曝光、点击、加购、下单、支付等事件,事件结构定义如下:
想检测连续 3 次下单,但都没有支付的数据,向用户发送促销消息。需要匹配 2 个单个模式成为一个组合模式:
- 连续 3 次下单。单个模式,模式因为有
量词从单例变成循环 - 支付。单个模式,无
量词是单例
1.3 模式组
对于模式组是对单个模式和组合模式的更进一步结合,比如对检测连续 3 次下单,但都没有支付的数据,发生一次可能是用户没有购买意愿可向用户发送促销消息促成交,发生 10 次判断用户可能是刷单用户。因此需要检测模式整体发生了 10 次:
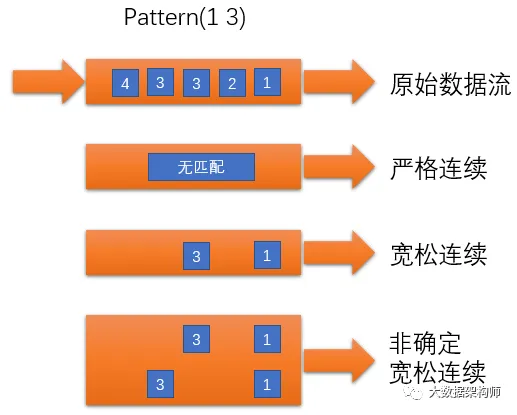
1.4 连续性
连续性指的是不同事件之间的是否连续,它有 2 个场景:
- 在
单个模式中,如果对单例模式增加量词即可变成循环模式。比如检测用户连续转账 5 次且每次转账金额大于 10000 的行为,对于连续转账中的连续的定义:是真正的连续事件,还是转账事件中间可以夹杂着登陆、登出事件。 - 将多个
单个模式组合成组合模式。比如连续 3 次下单,但没有支付的行为中,在连续 3 次下单和支付行为中间,是连续的,还是可以夹杂着曝光、点击、加购等事件。
在模式序列中,把多个单个模式组合成组合模式的条件为连续条件
- 严格连续: 期望所有匹配的事件严格的一个接一个出现,中间没有任何不匹配的事件。
- 松散连续: 两个匹配事件的相对顺序,忽略匹配的事件之间的不匹配的事件。
- 不确定的松散连续: 可以重复使用之前已经匹配过的事件,以同一个事件作为开始匹配,更进一步的松散连续,允许忽略掉一些匹配事件的附加匹配。


配置方式:
组合模式。next()。严格连续followedBy()。松散连续followedByAny()。不确定的松散连续
模式组。start.next( Pattern.<Event>begin("next_start").where(...).followedBy("next_middle").where(...) ).times(3)start.followedBy( Pattern.<Event>begin("followedby_start").where(...).followedBy("followedby_middle").where(...) ).oneOrMore();start.followedByAny( Pattern.<Event>begin("followedbyany_start").where(...).followedBy("followedbyany_middle").where(...) ).optional();
同时还可以配置Not语义的连接:
notNext(),如果不想后面直接连着一个特定事件notFollowedBy(),如果不想一个特定事件发生在两个事件之间的任何地方。
注意,Not语义有使用限制:
- 如果模式序列没有定义时间约束,则不能以
notFollowedBy()结尾。 - 一个
Not模式前面不能是可选的模式(有optional()量词)。
对于单例模式,通过增加量词变成循环模式时,重复次数的连续性配置如下:
- 严格连续。
consecutive()与oneOrMore()和times()一起使用, 在匹配的事件之间施加严格的连续性, 也就是说,任何不匹配的事件都会终止匹配(和next()一样)。 - 松散连续。默认行为,即
followedBy() - 不确定性连续。
allowCombinations()与oneOrMore()和times()一起使用, 在匹配的事件中间施加不确定松散连续性(和followedByAny()一样)
1.5 时间约束
除了指定事件的重复次数和不同事件之间的组合,还可以添加时间约束:
循环模式。比如 1 小时内检测用户连续转账 5 次且每次转账金额大于 10000 的行为组合模式。比如连续 3 次下单,但 10 分钟内没有支付的行为
1.6 复杂条件
单个事件的检测规则可以很简单,也可以很复杂,但是都是针对单个事件,条件也可以跨多个事件。
1.6.1 案例1
比如某日销售额超过前 3 天的平均值 20%,数据流为每日销售额对象。
针对上面数据,判断 20251014 销售额是否超过 20251011 + 20251012 + 20251013 平均值 20%。
这种场景下,需获取当日销售额的前 3 天销售额,计算前 3 天销售额的平均值,继而和当天销售额进行比较。
实现方式如下:
因为是计算每日销售额是否大于前 3 天销售额,因此前 3 天的数据是一个滑动窗口效果。
todo:判断 context 是否可以获取正在匹配的模式的数据
todo: 如何实现滚动
1.6.2 案例2
以监控告警为例:第一次告警发生后,30s 内发生第二次告警,进行告警升级,第一次告警邮件通知,第二次升级为电话通知。
需要配置 2 条规则:
也可以配置 1 条规则:
- 通过把第二次告警事件的发生次数设置为
optional()可保证只有一次告警的时候也能发出 - 因为设置了时间约束,30s 内,可通过超时函数获取到只发生一次告警的事件
缺点是在第一次告警发生后,需等待 30s 查看是否有第二条告警事件,导致第一次告警后不能及时发送告警通知
比较好的实现是把 30s 的时间间隔放置到发送告警消息时,如果只有 1 条消息,发送邮件通知,如果有 2 条消息,且 2 条消息的时间间隔低于 30 s,发送电话通知,否则发送邮件通知。
todo
- 告警静默。1 小时内只发送一次
1.6.3 案例3
多模式的匹配条件
2.匹配后跳过策略
对于一个给定模式 b+ c 和数据流 b1 b2 b3 c,模式 b+ 是 SQL 的语法,表示 1 到多个 b。数据流中有 3 个 b 事件:b1 b2 b3 都会命中 b+ 的规则,那么同一个事件可能会分配到多个成功的匹配上,用户可以指定匹配后跳过策略,控制一个事件会分配到多少个匹配上。
总共有 5 种策略:
- NO_SKIP。每个成功的匹配都会被输出
- SKIP_TO_NEXT。丢弃以相同事件开始的所有部分匹配
- SKIP_PAST_LAST_EVENT。丢弃起始在这个匹配的开始和结束之间的所有部分匹配
- SKIP_TO_FIRST。丢弃起始在这个匹配的开始和第一个出现的名称为PatternName事件之间的所有部分匹配
- SKIP_TO_LAST。丢弃起始在这个匹配的开始和最后一个出现的名称为PatternName事件之间的所有部分匹配
详细说明如下
| 策略 | 结果 | 描述 |
|---|---|---|
| NO_SKIP | b1 b2 b3 cb2 b3 cb3 c | 找到匹配b1 b2 b3 c之后,不会丢弃任何结果。 |
| SKIP_TO_NEXT | b1 b2 b3 cb2 b3 cb3 c | 找到匹配b1 b2 b3 c之后,不会丢弃任何结果,因为没有以b1开始的其他匹配。 |
| SKIP_PAST_LAST_EVENT | b1 b2 b3 c | 找到匹配b1 b2 b3 c之后,会丢弃其他所有的部分匹配。 |
| SKIP_TO_FIRST(b) | b1 b2 b3 cb2 b3 cb3 c | 找到匹配b1 b2 b3 c之后,会尝试丢弃所有在b1之前开始的部分匹配,但没有这样的匹配,所以没有任何匹配被丢弃。 |
| SKIP_TO_LAST(b) | b1 b2 b3 cb3 c | 找到匹配b1 b2 b3 c之后,会尝试丢弃所有在b3之前开始的部分匹配,有一个这样的b2 b3 c被丢弃。 |
详情参考:匹配后跳过策略
3.限制条件
- 不可逆。
- 有序。A -> B -> C,A -> C -> B,B -> A -> C,B -> C -> A,C -> A -> B,C -> B -> A