内存管理
原因
参考链接:
基于 JVM 的数据引擎需要将大量数据加载到内存中,在高性能方面会受到 JVM 内存管理的限制:
- Java 对象存储密度低。一个只包含 boolean 属性的对象占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上只需要一个bit(1/8字节)就够了。
- GC 问题。无论是 minor gc 还是 full gc,都会有 STW 问题(Stop The World),造成应用停顿,数据处理发生抖动。尤其是大数据场景下,分配越多的内存 GC 停顿时间会越长
- OOM 问题。将大量数据加载到内存中,会有一定概率超出 JVM 内存导致 OOM
Flink 中的 TaskManager 中堆内存分为 3 部分:
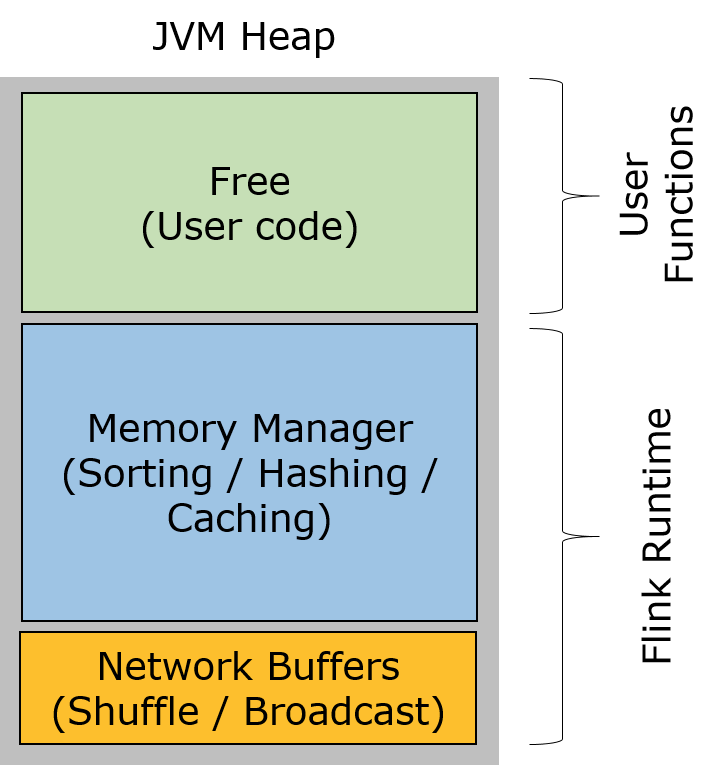
- Network Buffers: 一定数量的32KB大小的 buffer,主要用于数据的网络传输。在 TaskManager 启动的时候就会分配。默认数量是 2048 个,可以通过
taskmanager.network.numberOfBuffers来配置。(阅读这篇文章了解更多Network Buffer的管理) - Memory Manager Pool: 这是一个由
MemoryManager管理的,由众多MemorySegment组成的超大集合。Flink 中的算法(如 sort/shuffle/join)会向这个内存池申请 MemorySegment,将序列化后的数据存于其中,使用完后释放回内存池。默认情况下,池子占了堆内存的 70% 的大小。 - Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager 的数据结构使用的。因为这些数据结构一般都很小,所以基本上这些内存都是给用户代码使用的。从 GC 的角度来看,可以把这里看成的新生代,也就是说这里主要都是由用户代码生成的短期对象。
Flink 内存管理的好处:
- **减少GC压力。**显而易见,因为所有常驻型数据都以二进制的形式存在 Flink 的
MemoryManager中,这些MemorySegment一直呆在老年代而不会被 GC 回收。其他的数据对象基本上是由用户代码生成的短生命周期对象,这部分对象可以被 Minor GC 快速回收。只要用户不去创建大量类似缓存的常驻型对象,那么老年代的大小是不会变的,Major GC也就永远不会发生。从而有效地降低了垃圾回收的压力。另外,这里的内存块还可以是堆外内存,这可以使得 JVM 内存更小,从而加速垃圾回收。 - 避免了OOM。所有的运行时数据结构和算法只能通过内存池申请内存,保证了其使用的内存大小是固定的,不会因为运行时数据结构和算法而发生OOM。在内存吃紧的情况下,算法(sort/join等)会高效地将一大批内存块写到磁盘,之后再读回来。因此,
OutOfMemoryErrors可以有效地被避免。 - **节省内存空间。**Java 对象在存储上有很多额外的消耗(如上一节所谈)。如果只存储实际数据的二进制内容,就可以避免这部分消耗。
- **高效的二进制操作 & 缓存友好的计算。**二进制数据以定义好的格式存储,可以高效地比较与操作。另外,该二进制形式可以把相关的值,以及hash值,键值和指针等相邻地放进内存中。这使得数据结构可以对高速缓存更友好,可以从 L1/L2/L3 缓存获得性能的提升(下文会详细解释)。
参考链接
目录