概念
基础架构和概念
Flink 介绍
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
- 有状态计算
- 状态接口。算子状态、键值状态、广播状态
- 容错机制。可从 checkpoint 和 savepoint 恢复
- 轻量级异步分布式快照算法
- 流批一体。一套代码可以同时进行流处理和批处理
- 提供高抽象层的 API
- SQL API
- Table API
- DataStream API
- Statefule Stream Processing API
- 内置多种算子(operator)。
- source
- transformation
- sink
- 多语言支持。支持 Java、Scala 和 Python
流处理
流是数据的天然形态,无论是网站的事件流、股票的交易,还是工厂机器的传感数据等都是数据流,但是分析数据的时候,用户需要按照 有界流(bounded) 或 无界流(unbounded)组织数据,无论选择有界还是无界,都会对后续的处理有重大的影响。
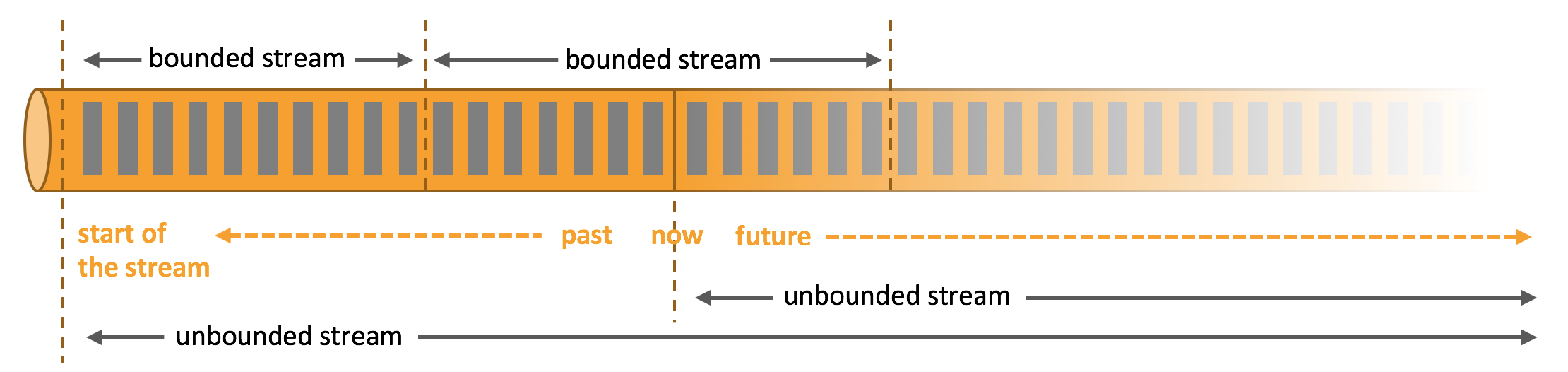
- 批处理。批处理是有界流数据处理范式。批处理时用户可以读取整个数据集,执行排序,计算全局指标,或产出一个总结报表。
- 流处理。流处理处理无界数据流。无界流不会结束,流处理需处理源源不断到来的数据。
Flink 的组件及其作用
参考链接:
在 Flink 的架构中,Flink 文档在不同场景下给出了不同的解释:
- 部署。
- Client
- Flink 组件。JobManager、TaskManager
- 外部组件。
- 运行。在运行架构中,Flink 集群包含 JobManager 和 TaskManager,不包含 Client。Client 只用来向 JobManager 发送 dataflow,之后 Client 就可以与 JobManager 断开连接(detached mode),也可以不断开接收处理结果(attached mode)
其中 JobManager 和 TaskManager 作用如下:
- JobManager。
Dispatcher。提供 REST API 接收 Flink 应用提交,每次收到新的应用会启动一个JobMaster处理新的任务。同时提供 Flink web ui 服务JobMaster。管理单个 JobGraph 执行。Flink 集群可以同时执行多个任务,每个任务有自己的JobMasterResourceManager。负责 Flink 集群中资源(task slot)的分配和回收。Flink 为不同的环境和资源提供者实现了不同的ResourceManager
- TaskManager。TaskManager 提供资源执行 dataflow 中具体的 task,在不同的 task 之间传输和 buffer 数据流,执行 checkpoint、savepoint。TaskManager 中最小的资源调度单位为
task slot。
Flink 部署架构图:

Flink 运行架构图1:

Flink 运行架构图2:

Flink 运行架构图3:

部署,运行模式。session、application,k8s,yarn
operator chain,并行度,task & sub-task
参考链接:
Flink 应用经过编译后变成一个 Logical Graph,Logical Graph 是一个 DAG(有向无环图),在 DAG 中每个节点就是一个算子(operator),Flink 默认会尽量将算子(operator)连接到一块,组成算子链(operator chain),将算子(operator)连接到一起,可以减少数据在算子(operator)间传输时网络和序列化/反序列化消耗,降低延迟提高吞吐。
算子连接到一块的条件:
- 并行度一致
- 上下游算子之间传输策略为 Forward
- 算子位于同一 task slot 共享组
用户可以干预算子 chain 过程:
startNewChain()disableChaining()
Flink 应用在 Client 经过编译后最后提交到 Flink 集群的是 JobGraph,Flink 集群会将 JobGraph 转变成 ExecutionGraph,ExecutionGraph 中的节点即为 Task,每个 Task 为一个 operator(未 chain 到一起的 operator) 或 operator chain。
Task 可以并行运行,Task 可以分成多少个 Sub-Task 由并行度决定。
设置并行度的方式有 4 种,优先级由高到低:
- 代码中设置。
- 代码中全局设置
- 启动任务时通过参数指定
- flink-conf.yaml 中指定
todo 最大并行度
不同的 operator 上下游通过网络连接到一起,数据在 operator 之间的传输策略:
- Forward。默认传输策略。
- Rebalance。当 Forward 不满足时默认传输策略。
- 出现数据倾斜时才会主动使用
- Rescale。Rescale 不是完全将数据轮询下发到下游算子的所有 SubTask 上,而是轮询下发到下游算子的一部分 SubTask 上。
- Shuffer。类似 Rebalance,在选择下游算子时随机选择,Rebalance 则是轮询选择。
- KeyGroup。
- KeyGroup 也称作哈希传输策略,Flink Web UI 显示为 HASH
- Broadcast
- Global
- Custom Partition
checkpoint,savepoint,state,watermark,异步快照算法,背压
参考链接:
exactly-once,at-least-once,端到端一致性
failure strategy
窗口
join
内存管理
其他
Flink 内部处理协调、网络、checkpoint,failover,API,算子,资源管理等功能的代码位于 flink-dist.jar,为了保证 Flink 核心的精简,只在 /lib 目录下存放必要的 jar,而将其他功能性的 jar 放入到 /opt 和 /plugins 目录下。如果用户有需要将 /opt 目录下的 jar 移入 /lib 和 /plugins 目录下即可。
另外连接三方数据源的 connectors 和 formats 不在 /lib 和 /plugins 目录下,这样是为了避免用不到的代码存在 flink 运行环境中,需要用户在 flink 应用中按需添加。connectors 和 formats 相关代码也从 flink 仓库拆分到了独立的代码仓库。
序列化
参考链接:
异步IO
参考链接:
场景:关联维表数据
解决同步 I/O 低吞吐的 4 种解决方案:
- 提高算子并行度。一般在 map 或者 flatmap 中关联维表数据,可通过增加并行度提高吞吐。缺点:I/O 不是 CPU 密集型工作,提高并行度没有利用好分配的 CPU 资源,存在资源浪费
- 缓存加速。一般维表数据变化频率较低,可考虑缓存数据。将较慢的存储介质缓存在快速的存储介质中,如将 mysql 中数据缓存在 redis 甚至 state 中,缓存未命中时,查询 mysql,并更新缓存。
- 异步 I/O。将同步 I/O 变为异步 I/O
- 攒批处理。类似微服务中合并接口请求,也可以在 flink 中实现每攒够 20 条数据或到达 3s,批量请求维表数据。
异步处理,使用异步 I/O 时,需数据库客户端支持异步请求,如果客户端不支持异步请求,需通过线程池将同步调用转为异步调用。
顺序性。异步 I/O 返回的数据顺序是否和同步 I/O 顺序保持一致?答案是默认是乱序的,Flink 异步 I/O 提供了两种模式:
- 有序模式。即异步 I/O 返回的数据顺序和数据处理顺序一致
- 无序模式。
异步 I/O 与事件时间。
在无序模式下,异步 I/O 返回的数据顺序和数据输入顺序不一致,而错误的事件时间会使时间窗口产出错误的结果。那么在异步 I/O 之后应用事件时间窗口是否可行?答案是可以的。虽然是无序模式,异步 I/O 算子依然可以保证事件时间下的时间窗口计算结果正确。异步 I/O 算子通过 watermark 建立数据产出顺序的边界,相邻的两个 watermark 之间的数据可能是无序的,但是同一个 watermark 前后的数据依然是有序的。
时间语义&时间窗口
参考连接:
时间语义:
- 事件时间。event time
- 处理时间。process time
- 摄入时间。ingest time
时间窗口:
- 滚动窗口。时间计算频率和时间计算长度一致的窗口
- 滑动窗口。时间计算频率和时间计算长度不一致的窗口,滚动窗口算是滑动窗口的一个特例
- 会话窗口。
- 全局窗口。
Watermark
水位线
数据会乱序,针对乱序的数据或延迟的数据,窗口该如何处理:
- 窗口重新计算数据,修正结果。通过 allowLateNess 实现
- 将延迟数据收集起来,另行处理。通过 sideOutPut 实现
- 丢弃延迟数据。默认实现
乱序/延迟解决方案:watermark / allowLateNess / sideOutPut:
- watermark。防止 数据乱序 / 指定时间内获取不到全部数据
- allowLateNess。将窗口关闭时间延迟一段时间
- sideOutPut。兜底操作,当指定窗口已经彻底关闭后,把接收到的延迟数据放到侧输出流,让用户决定如何处理
watermark 实际上是一个 unix ms 时间戳,表示早于该时间的数据已全部抵达,不会再有时间小于水位线的数据输入。watermark 只能增大,不能减小。
watermark 类型:
- 周期性
watermark 传输。watermark 生成后在经过 operator chain 传输过程中,是如何传播的?复用现有的 operator chain 中 subtask 的连接方式进行传输。watermark 在 source 生成,一直传输到 sink,会经过所有的 operator。
在多并行度下
状态
参考链接:
参数
参考链接:
Flink SQL
如何优化 checkpoint 过大问题,如何用 flink sql 去重
基础
Operator&OperatorChain、Task&SubTask、并行度、Slot
最大并行度
SubTask 占据 Slot,不同 Task 可以共享 Slot
Slot 共享组
chain 一起的条件:
- 并行度相同
- 一对一传输
- 位于同一个 slot 共享组
修改 chain:
startNewChain()disableChaining()
类型系统
文档链接:
Flink 在与外部存储系统(文件系统、消息队列、数据库等)交互时,需要读取、写入数据,数据在 Flink 内部不同算子之间传输时(非 chain 状态)时也会经历序列化和反序列化。Flink 的类型系统即内部可以识别的类型,以及内部采用的序列化框架。
DataStream
在使用 DataStream 进行开发时,一般使用 POJO、Tuple、基本类型等即可满足。Function 都是算子,默认情况下 Flink 在编译时都能自动识别、推导出来,少部分场景下无法识别、推导时,需要用户主动提供 Function 和 DataStream 类型。
UDF
在 Flink SQL 中,当需要使用 UDF 扩展功能时,如果 UDF 使用的都是基本类型,一般都可以自动识别。如果是比较复杂的 POJO 或者 Array 等类型,就需要提供 type hints,辅助 Flink 识别 UDF 使用的类型,参考:Type Inference。
Source & Sink
这其实已经不是类型系统,而是和外部系统的序列化。如 kafka 中的数据以 bytes 存储,读取和写入的时候都需要指定序列化器和反序列化器,实现数据的序列化和反序列化。
Kafka connector 参考:
在 source 和 sink 中需指定 KafkaRecordDeserializationSchema 和 KafkaRecordSerializationSchema,Flink 内部内置了一些简单的实现:
SimpleStringSchema。将 Kafka 中的数据读取为 string,或以 string 写入。一般在读取和写入时需搭配一个MapFunction将 string 转化为 POJO 或将 POJO 转化为 string。JsonDeserializationSchema和JsonSerializationSchema。如果 Kafka 中数据为 json 格式,想直接将 json 格式序列化为 POJO,可以使用
如果以上不满足需求,用户还可以直接提供 KafkaRecordDeserializationSchema 和 KafkaRecordSerializationSchema 实现。
状态
有状态计算要点:
- 本地化状态访问。相比使用 redis、hbase 作为状态存储,Flink 本地的状态访问速度会远超 redis、hbase。某业务场景中为了确保 Flink 任务变更时状态不丢失,将部分核心数据存储到 redis 中,后随着流量增长,Flink 任务处理能力跟不上,后将 redis 中数据更换到 Flink 状态中,处理能力满足需求。
- 精确一次性状态快照算法
- 统一的状态接口
统一的状态接口
状态类型:
- 算子状态
- ListState。平均分割重分布策略
- UnionListState。合并重分布策略
- 键值状态
- ValueState
- MapState
- ListState
- ReducingState
- AggregatingState
- 广播状态。
- 一种特殊的算子状态,每个 SubTask 的状态都是一致的。
- 状态持久化。所有 SubTask 的状态都是一致的,checkpoint 时只需要持久化任一 SubTask 的状态即可。实际上 Flink 依然将所有 SubTask 的状态都持久化了
- 状态重分布。异常容错时,需将快照分发到所有 SubTask。
- MapState。与键值状态的 MapState 一样。
- 使用方式
- 定义广播数据流、广播状态描述符、和主数据流
- 将两条数据流通过
connect()方法进行连接 - 定义广播处理函数,在广播处理函数中通过状态描述符获取广播状态
- 一种特殊的算子状态,每个 SubTask 的状态都是一致的。
在业务中有个增加人工修改逻辑的功能,当人工干预数据进行人工调整时,Flink 任务的相关数据以人工修改数据为准。实现时也是使用 connect() 函数把人工修改数据流和主数据流连接到一起。它和广播状态的场景有点区别:广播状态需要 SubTask 的所有状态一致,人工修改的数据有自己的 key,主数据流经过 keyBy() 后,人工修改的数据只需要分发到 key 所在的 SubTask。
状态问题:
- 算子恢复。
- 当算子并行度增加/减少时,状态如何重分布?Flink 内部已经支持。
- 增、减算子时,状态如何恢复?需要用户为每个算子添加唯一 ID,在任务停止前创建 savepoint,使用 savepoint 重启任务
- 状态 POJO 调整。如 ValueState 中对象使用的是 POJO。POJO 新增字段时会导致状态无法回复
- 大状态问题。状态使用场景有 2 个:
- 缓存场景。对于超过一定时限的数据即不在使用的状态添加 TTL 配置,确保状态无用时会被自动删除
- 存储问题。
- 检查存储的数据是否都是必要的。
- 可插拔状态后端。对于大数据量,需要仔细考虑使用的状态后端能够满足存储需求。
- HashMap
- RocksDB
Watermark
参考链接:
Watermark 是一个单位为 ms 的时间戳,用于维护和标识事件时间时钟。s
时间类型:
- 处理时间(processing time)。
- 事件时间(event time)。
- 摄入时间(ingestion time)。
设置方式。推荐在 Source 上设置,越早越好
DataStream#assignTimestampsAndWatermarks(WatermarkStrategy)。在任意 DataStream 上都可以随时设置StreamExecutionEnvironment#fromSource(Source, WatermarkStrategy, ...)。在 Source 上设置,推荐方式。
WatermarkStrategy 包含 #createTimestampAssigner()和 #createWatermarkGenerator() 两个方法:
TimestampAssigner<T>createTimestampAssigner(TimestampAssignerSupplier.Context context)。构建TimestampAssigner(时间戳分配器)。TimestampAssigner用于从数据中获取事件时间戳WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context)。构建WatermarkGenerator(Watermark 生成器)。WatermarkGenerator用于给数据流插入Watermark
Timestamps/Watermarks 算子会先使用 TimestampAssigner 获取数据的事件时间戳,给这条数据标记事件时间戳,然后通过WatermarkGenerator 生成 Watermark,插入数据流。WatermarkGenerator 定义如下:
上述 2 个接口都可以生成 Watermark,只不过用于不同场景:
- 周期性 Watermark 生成器(Periodic WatermarkGenerator)。默认的时间间隔为处理时间的 200ms,广泛使用
- 标记 Watermark 生成器(Punctuated WatermarkGenerator)。使用场景较少
- 缺点。当数据量过多时,会生成过多的 watermark,尤其是 watermark 和数据量达到 1:1 时,有多少数据就会有多少 watermark,影响正常的数据处理。过多的 watermark 大部分是无效 watermark,只有少量能够触发下游算子的窗口计算。
内置类型
WatermarkStrategy#noWatermarks()。不生成WatermarkStrategy#forMonotonousTimestamps()。数据单调递增,无乱序和延迟场景,内部实现为AscendingTimestampsWatermarkWatermarkStrategy#forBoundedOutOfOrderness(Duration)。固定延迟的 Watermark 生成器,当存在乱序的数据时可以使用,但是要求(非强制要求)数据的乱序程度在有限(固定)范围内(Watermark 不能完全处理乱序和延迟)。内部实现为 BoundedOutOfOrdernessWatermarks`WatermarkStrategy#forGenerator(WatermarkGeneratorSupplier)。自定义
使用方式:
窗口(DataStream)
时间窗口
DataStream API 提供的时间窗口的骨架如下:
DataStream.windowAll() 方法底层的逻辑是通过 DataStream.keyBy(new NullByteKeySelector()) 方法实现的。NullByteKeySelector 中的 getKey() 方法的实现逻辑是返回一个固定的值 0,这就说明所有数据的 key 都是 0,这也印证了在 DataStream 上进行时间窗口操作等同于将所有的数据都划分为同一类后再进行时间窗口操作。注意,在生产环境中使用DataStream.windowAll() 方法时,由于所有数据的 key 都为 0,所以上游算子会将所有的数据发送到时间窗口算子的同一个 SubTask 中进行处理,时间窗口算子的并行度会被 Flink 强制设置为 1,这有极大概率会产生数据倾斜。因此该操作并不常用。
reduce()、aggregate()、apply()、process() 这 4 种方法都可以用于指定窗口数据的处理逻辑,这些方法可以将WindowedStream 转换为 SingleOutputStreamOperator。SingleOutputStreamOperator 继承自 DataStream,代表窗口化的数据流经过窗口处理函数的处理后变为普通的数据流。
Flink 内置的 4 种窗口:
- Tumble Window
- SlidingWindow
- Session Window
- Global Window
滚动窗口
偏移量参数通常用于解决天级别窗口的时区问题。如一分钟的滚动窗口一般为 2024-10-08 11:23:00 ~ 2024-10-08 11:24:00,如果需要将窗口的时间起始点从 00 调整为 30,即 2024-10-08 11:23:30 ~ 2024-10-08 11:24:30,就可以设置一个 30s 的偏移量。
滑动窗口
会话窗口
窗口处理函数
窗口处理函数分为 3 类:
- 全量窗口处理函数。缺点:状态大、执行效率低,优点:可以实现赞批处理效果,尤其是外部 I/O 访问
apply(WindowFunction)process(ProcessWindowFunction)。ProcessWindowFunction 是 WindowFunction 增强版本,ProcessWindowFunction 相比 WindowFunction 多了获取 Flink 作业运行时上下文的功能。ProcessWindowFunction 在没有提高用户开发成本的基础上,提供了更多的上下文信息,推荐在生产中直接使用 ProcessWindowFunction- 访问窗口信息:通过 Context 的
window()方法获取当前时间窗口的开始时间和结束时间 - 访问时间信息:通过 Context 的
currentProcessingTime()方法和currentWatermark()方法,分别获取当前 SubTask 的处理时间以及事件时间的 Watermark - 访问状态:通过 Context 的
windowState()方法访问当前 key 下窗口内的状态,通过 Context 的globalState()方法可以访问当前 key 的状态,这里访问的状态是跨窗口的。最常用的 - 旁路输出:通过 Context 的
output(OutputTag<X> outputTag, Xvalue)方法可以将数据输出到指定旁路中,入参outputTag是旁路的唯一标识,value 是要输出到旁路中的数据。
- 访问窗口信息:通过 Context 的
- 增量窗口处理函数。可有效缓解全量窗口处理函数中提到的状态大和执行效率低问题。
reduce(ReduceFunction)。ReduceFunction 要求输入数据、聚合结果、输出数据的类型一致aggregate(AggregateFunction)。AggregateFunction 是 ReduceFunction 的一个增强版本。由于 AggregateFunction 更具通用性,因此推荐大家使用 AggregateFunction。
- 增量、全量搭配使用。增量窗口处理函数只有执行数据计算的方法以及参数,并不能获取作业运行时的上下文信息,在某些场景下,SubTask 运行时的上下文、时间窗口信息对数据处理来说是必需的。
- DataStream API 提供了将增量窗口处理函数和全量窗口处理函数结合在一起的功能。WindowedStream 上的
reduce()、aggregate()方法除了可以传入ReduceFunction、AggregateFunction外,还可以传入WindowFunction或者ProcessWindowFunction。以AggregateFunction搭配ProcessWindowFunction的组合为例,窗口算子在执行时,对输入的每条数据依然会使用AggregateFunction执行增量的数据处理,并在窗口触发器被触发时,使用AggregateFunction的getResult()方法获取结果。这时窗口算子不会将结果直接发给下游算子,而是将这条结果数据放入Iterable集合(Iterable集合内只有 1 条数据),作为ProcessWindowFunction中process()方法的入参传递给ProcessWindowFunction执行,这时我们就可以在ProcessWindowFunction中获取 SubTask 的上下文信息了
- DataStream API 提供了将增量窗口处理函数和全量窗口处理函数结合在一起的功能。WindowedStream 上的
窗口触发器
- Flink 预置的滚动窗口、滑动窗口、会话窗口分配器中提供的默认窗口触发器分为以下两种
- ProcessingTimeTrigger:处理时间语义的触发器,会为窗口注册处理时间的定时器。当处理时间达到处理时间定时器的时间时,触发窗口计算,否则继续等待触发
- EventTimeTrigger:事件时间语义的触发器,会为窗口注册事件时间的定时器。当 Watermark 达到事件时间定时器的时间时,触发窗口计算,否则继续等待触发
- 除上述两种常见的窗口触发器之外,Flink 还预置了以下 6 种窗口触发器
ContinuousProcessingTimeTrigger.of(Time interval):处理时间语义下,按照 interval 间隔持续触发的触发器ContinuousEventTimeTrigger.of(Time interval):事件时间语义下,按照 interval 间隔持续触发的触发器,功能和ContinuousProcessingTimeTrigger相同CountTrigger.of(long maxCount):计数触发器,在窗口条目数达到maxCount时触发计算。计数触发器用于计数窗口DeltaTrigger.of(double threshold, DeltaFunction<T>deltaFunction, TypeSerializer<T>stateSerializer):阈值触发器,使用deltaFunction利用原始数据计算一个数值,接下来判断该数值是否超过了用户设置的threshold,如果超过了threshold则触发窗口计算ProcessingTimeoutTrigger.of(Trigger<T, W> nestedTrigger,Duration timeout, boolean resetTimerOnNewRecord, boolean shouldClearOnTimeout):处理时间语义下的超时触发器,该触发器需要和其他触发器搭配使用,其中nestedTrigger是搭配使用的窗口触发器,timeout为处理时间的超时时间PurgingTrigger.of(Trigger<T, W>nestedTrigger):清除触发器。可以将任意类型的触发器加上清除(Purge)的功能,如果一个触发器包含 Purge 属性,那么在窗口触发器触发窗口计算后,会将窗口内的原始数据清除,入参nestedTrigger就是需要被转换为清除触发器的触发器
计数窗口
常见问题和解决方案
常见问题:
- 事件时间窗口不触发计算。
- 没有正确分配 Watermark。可通过 Flink Web UI 的作业详情模块中时间窗口算子所有 SubTask 的 Watermark 列表去查看。
- 未配置
- 配置错误。Watermark 是 ms 级别的时间戳,需注意发送的 Watermark 是否是 ms 级别
- Watermark 过少。source 或上游算子发送的数据过少。如果是 source 中数据过少可以很容易发现,但当 source 数据很多,但是定义 Watermark 的地方比较靠后,经过中间算子的数据处理逻辑后剩下的数据非常少。此问题也可通过 Flink Web UI 定位,只要
Timestamps/Watermarks算子的输出数据量非常少,时间窗口算子的Watermark推进得很慢,就是这个问题。常用的解决方案是尽可能在数据源端就分配 Watermark。 - Watermark 不对齐。由于 SubTask 在收到上游算子多个 SubTask 的 Watermark 时,会取最小值作为当前的事件时间时钟,所以当 Flink 作业数据源存储引擎的多个分区的数据时间相差很大时,会出现一个 SubTask 的 Watermark 拖了其他 SubTask 后腿的情况(如 Kafka 中 topic 下不同 partition 数据倾斜,部分 partition 数据多,消费慢)。该场景被称为多数据源 Watermark 不对齐或者单数据源多个分区 Watermark 不对齐。定位问题时可以查看 Flink Web UI 中算子 SubTask 的 Watermark 来对比 Watermark 差值是否过大来定位。
- 某个数据源在某一段时间内没有数据持续输入而导致 Watermark 推进慢或者不推进,可以使用
WatermarkStrategy提供的withIdleness()方法来检测某个数据源是否是空闲数据源,如果是,就可以将该数据源标记为空闲状态。
- 某个数据源在某一段时间内没有数据持续输入而导致 Watermark 推进慢或者不推进,可以使用
- 没有正确分配 Watermark。可通过 Flink Web UI 的作业详情模块中时间窗口算子所有 SubTask 的 Watermark 列表去查看。
- 事件时间窗口数据乱序。
- 数据乱序问题会导致时间窗口计算结果错误。
- 可以通过 Flink Web UI 中算子的 Metrics 模块中的 numLateRecordsDropped 指标来查看当前 SubTask 丢弃了多少条迟到的数据。旁路输出的方式将迟到的数据输出,Flink的SubTask将不会统计numLate-RecordsDropped指标
- Watermark 缓解数据乱序
- AllowLateness(允许延迟)机制。让窗口随着Watermark的推进而正常触发,窗口先不要关闭和销毁,让乱序的数据依然能被放入窗口,重新触发计算
- SideOutput
windowAll()方法导致数据倾斜。- 数据倾斜问题的方法也很简单,那就是分而治之,包括分桶和合桶两步。
多流操作
union
参考链接:
将多个 DataStream 连接到一起,不同 DataStream 之间的数据无序,来自同一条流的 DataStream 数据有序。
union 操作要求 DataStream 数据类型一致,因此一般需要在 DataStream union 到一起前需要通过 map 或 flatmap 算子进行数据类型转换。
union 操作代表的是数据流的合并过程,它控制的是数据的传输过程,而非数据的计算过程,所以没有专门的算子来完成 union 操作,在这个作业的 Flink Web UI 的逻辑数据流图中看不到有一个专门称作 union 的算子,只能看到多条数据流进行了合并,而 Map、Filter 操作在逻辑数据流图中是有对应的 Map、Filter 算子的。
connect
参考链接:
connect 功能和 union 操作一样,也是数据合并,但是 connect 不要求 DataStream 数据类型一致:
多条 DataStream 经过 connect 后变成 ConnectedStreams,在 ConnectedStreams 上可以使用 CoMap 和 CoFlatMap 操作将两条不同类型的输入数据流转换成同一种数据类型的输出数据流。
Join
Window Join
参考链接:
基于窗口的 join 将无界数据流转化为有界数据流,从而可以实现 join 操作。Flink 中的窗口操作分为时间窗口和计数窗口,这里的窗口指的是时间窗口。窗口可以使用滚动窗口、滑动窗口和会话窗口
apply 操作支持:
- JoinFunction
- FlatJoinFunciton
join 操作指的是Inner Join,如果任一 DataStream 没有数据,则会因为没有关联上不会输出数据。如果要实现没有关联上也要输出数据,需要使用 CoGroup。
Window CoGroup
CoGroup 是 Outer Join(比如 Left Join、Right Join、Full Join)。
apply 操作支持:
- CoGroupFunction
Interval Join
时间窗口关联以及 CoGroup 操作有一个共同点,那就是只有相同时间窗口内的数据才可以进行关联操作。然而有些操作天然是有先后顺序的,比如先曝光后点击,先下单后付款。那么当曝光事件发生在窗口的临界点时,点击事件往往落在下一个时间窗口内,从而曝光和点击无法关联。因此存在需求无论曝光事件的发生时间,关联曝光事件 5 分钟后的点击事件。
其他
在 Flink SQL 中支持 5 种 Join:
- regular join
- inner join
- outer join
- window join
- inner join。DataStream 提供了 Window Join
- outer join。DataStream 提供了 Window CoGroup
- interval join。DataStream 提供了 Interval Join
- temporal join
- lookup join。DataStream 提供了 Map、FlatMap、Async I/O
在 DataStream 中貌似缺少了 regular join。实际上 DataStream connect 操作可以实现 Flink SQL 中的 regular join 操作,只不过实现会比较复杂,没有其他操作那么开箱即用。
拆分
参考链接:
上述操作都是将多流合为单流,那么如何将单流拆成多流呢,答案是 SideOutput。