概念
数据湖
参考链接:
- 【Paimon系列】Apache Paimon 架构概述
- 【Paimon系列】Apache Paimon 基本概念
- 【Paimon系列】Paimon 并发控制
- 【Paimon系列】Paimon 目录(Catalog)管理
- 【Paimon系列】Paimon 表类型概览
- 【Paimon系列】Apache Paimon 数据类型
- 基于Pamion的流式数仓架构
- 基于Paimon的Streaming Lakehouse方案
- Paimon 实时数据湖开发
- Paimon 概览 | Apache Paimon 实时数据湖 Streaming Lakehouse 的存储底座
简介

paimon 作为数据湖存储,可在多种场景下替代现有解决方案,提供多功能的统一存储:
- 消息队列如 kafka。在 data pipeline 中作为数据源和中间层以保证数据的秒级延迟
- OLAP 系统如 clickhouse。将处理好的数据流式写入 olap 以提供 ad-hoc 查询
- 批存储如 hive。支持传统的批处理操作如
insert overwrite
为满足多功能的统一存储需求,paimon 提供的表和传统表有所区别:
- batch 模式。类似 hive 表,支持各种 batch sql。batch 模式下查询的是 latest snapshot。
- stream 模式。类似消息队列,查询 changelog 流,历史数据永不过期
paimon 表支持多种数据读写方式:
- 读
- batch 模式。类似 hive。读取历史快照数据
- stream 模式。从最新偏移量消费数据,或通过增量快照实现混合读取
- 写
- cdc 同步。流式同步数据库变更日志(如 mysql binlog)
- batch 模式。insert / overwrite 方式写入离线数据
同时 paimon 也支持多种底层存储,包括文件系统/对象存储(如 hdfs/s3)。
支持引擎如下:
- flink
- spark
- doris
- starrocks
- hive
- trino
paimon 表数据以列式存储,默认是 parquet,支持 orc、avro
文件布局
参考链接:

文件目录
-
快照(Snapshot)
- JSON文件记录表某一时刻的状态,包含 Schema 和关联的清单列表。支持时间旅行(Time Travel)回溯历史数据。
-
清单文件(Manifest)
- 记录 LSM 数据文件的变更(如增删),通过清单列表组织成链式结构。
-
数据文件
- 按分区存储,默认 Parquet 格式,支持 ORC/AVRO。
-
分区
与 Hive 分区兼容,通过日期、城市、部门等字段划分数据,显著提升查询效率
并发控制
参考:
当有多个任务在像同一张表写入数据时,如何保证数据正确性。
paimon 支持乐观锁支持多任务同时写入:
每个任务按照自己逻辑运行,提交时基于当前最新快照生成新的快照。因为多任务同时写入,提交时存在 2 种失败情况:
- snapshot 冲突。快照 id 被占用,别的任务已经生成了新的快照。当检测到这种情况时,任务重新基于当前最新快照生成新的快照。
- file 冲突。任务删除文件(逻辑删除)时,发现文件已经被其他文件删除。此时任务只能失败(对于 flink,任务失败后触发 failover 重启)
snapshot 冲突。
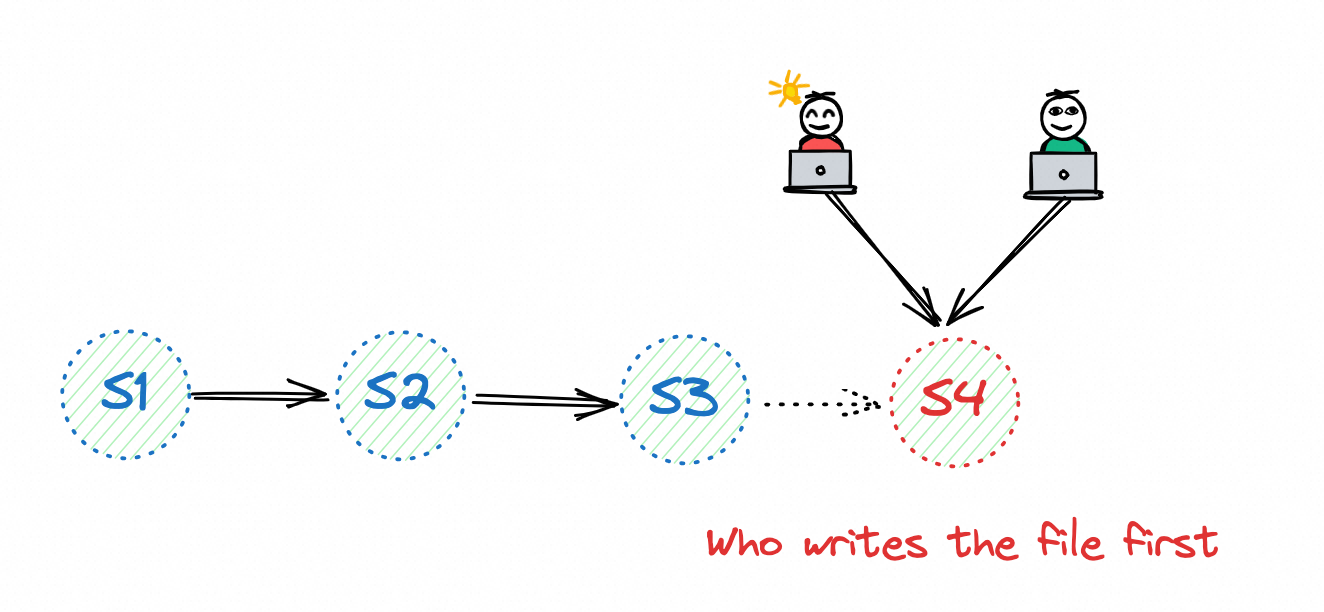
paimon 中快照 id 是唯一的,只要任务能将快照写入文件系统中,即成功。
paimon 提交快照时,使用文件系统的 rename 操作。hdfs 确保 rename 操作的事务性和原子性,而对象存储无法保证,需要在 hive 或 jdbc metastore 中启用 lock.enabled 选项。
file 冲突
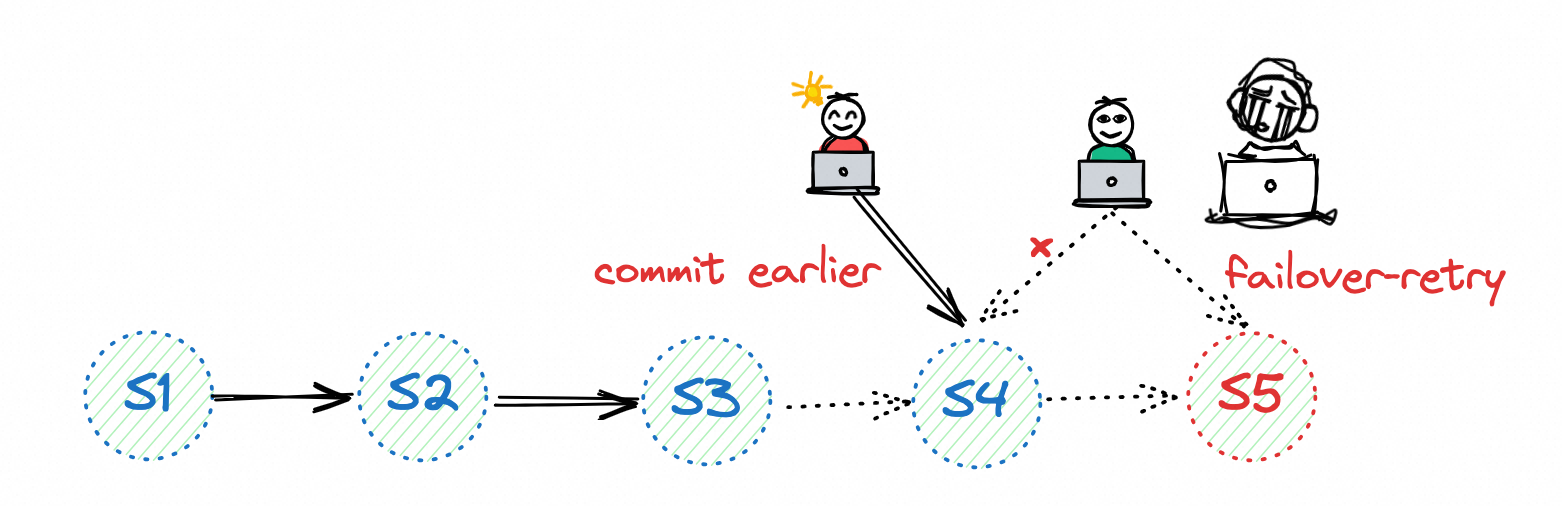
文件删除发生在 compaction 阶段,当多个任务同时写入时并同时开启 compaction,任务之间会不断触发 file 冲突,造成任务不停失败、触发 failover 重启。
在多个任务同时写入时,需确保只有一个任务开启 compaction。其余任务设置为 'write-only' = 'true'。
Catalog
参考链接:
类型
- FileSystem
- Hive
- JDBC
- Rest
表类型
参考链接:
paimon 支持多种表结构
- 主键表(primary key table)
- Append 表(no primary key table)。日志表
- view。需要 metastore 支持,在 SQL 中视图是一种虚拟表
- 格式表(format-table)。格式表指目录下包含多个具有相同格式的文件,主要是兼容 hive 表,因为 hive 是按照目录组织数据,一个文件目录即代表一个分区,分区下即包含指定格式的数据文件。文件格式支持:csv、json、parquet、orc
- 对象表(object-table)。为对象存储中的非结构化数据提供元数据索引,适合处理非结构化数据。
- 物化表(materialized-table)。简化 batch 和 stream data pipeline,提供一致性的开发体验。参考:Flink Materialized Table
主键表
带主键的表是 Paimon 中最常用的表类型之一。主键由一组列组成,确保每条记录的唯一性。Paimon 通过在每个桶内对主键进行排序来强制数据排序,从而支持流式更新和流式变更日志读取。
Append 表
无主键的表适用于追加数据的场景。与带主键的表不同,无主键的表不能直接接收变更日志(无法接收 changelog),也不能通过流式 upsert 更新数据(不支持 update)。它只能接收追加数据。
系统表
参考链接:
Function
参考链接: